When implementing an optimization for derived clause lookup myself, Amit Langote and David Rowley argued about the initial size of hash table (which would hold the clauses). See some discussions around this email on pgsql-hackers.
The hash_create() API in PostgreSQL takes initial size as an argument. It allocates memory for those many hash entries upfront. If more entries are added, it will expand that memory later. The point of argument was what should be the initial size of the hash table, introduced by that patch, containing the derived clauses. During the discussion, David hypothesised that the size of the hash table affects the efficiency of the hash table operations depending upon whether the hash table fits cache line. While I thought it's reasonable to assume so, the practical impact wouldn't be noticeable. I thought that beyond saving a few bytes choosing the right hash table size wasn't going to have any noticeable effects. If an derived clause lookup or insert became a bit slower, nobody would even notice it. It was practically easy to address David's concern by using the number of derived clauses at the time of creating the hash table to decide initial size of the hash table. The patch was committed.
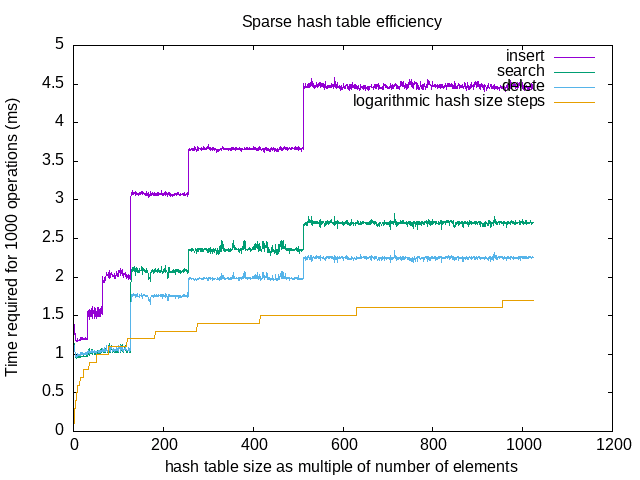
Within a few months, I faced the same problem again when working on resizing shared buffers without server restart. The buffer manager maintains a buffer look table in the form of a hash table to map a page to buffer. When the number of configured buffers changes upon a server restart the size of buffer lookup table also changes. Doing that in a running server would be significant work. To avoid that, we could create a buffer lookup table large enough to accommodate future buffer size needs. Even if the buffer pool shrinks or expands, the size of the buffer lookup table would not change. As long as the expansion is within the buffer lookup table size limit, it could be done without a restart. Buffer lookup table isn't as large as the buffer pool itself, thus wasting a bit of memory can be considered worth the flexibility it provided. However, David's concern about the hash table size came back again. This time though, I decided to actually measure the impact.
Experiment
/* Create a hash table, BufferTag maps to Buffer */info.keysize = sizeof(BufferTag);info.entrysize = sizeof(BufferLookupEnt);info.num_partitions = NUM_BUFFER_PARTITIONS;hashtab = hash_create("experimental buffer hash table", max_entries, &info,HASH_ELEM | HASH_BLOBS);
I invoked this function with varying hash table sizes but keeping the number of elements to 16384 (the default buffer pool size), using following query:
create table msmts_v as
select run,
hash_size,
(sparse_hashes(hash_size, 16 * 1024)).*
from generate_series(16 * 1024, 16 * 1024 * 1024, 8 * 1024) hash_size,
generate_series(1, 120) run;
Mind you, the query takes a lot of time to run. Following query is used to consolidate the results.
select hash_size/(16 * 1024) "hash size as multiple of number of elements",
round((log(hash_size/(16 * 1024))/log(64))::numeric, 1) as "logarithmic hash size steps",
avg(insert_time) insert,
avg(search_time) search,
avg(delete_time) delete
from msmts
group by hash_size
order by hash_size;